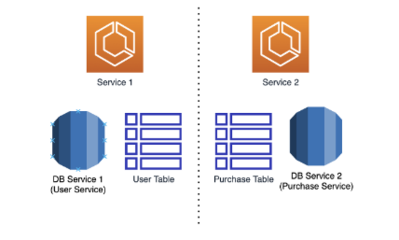
在微服务架构中,每个服务通常拥有独立的数据库,以支持服务间的解耦和自治。这种设计使得跨微服务的数据查询变得复杂,因为数据不再集中存储,而是分散在不同的服务边界内。要实现高效、可靠的跨微服务数据查询,需要结合多种策略和技术。以下是一些核心方法和实践:
- API组合模式:这是最常见的解决方案,通过一个协调服务(或API网关)调用多个相关微服务的API,然后将结果聚合返回给客户端。优点是实现简单,但可能导致多次网络调用,增加延迟,并可能引发服务间依赖的紧密耦合。
- 命令查询职责分离(CQRS):将读写操作分离,为查询专门设计一个或多个只读的数据存储(如视图数据库)。微服务在写入数据时,通过事件驱动机制(如消息队列)同步更新查询存储,从而实现跨服务数据的聚合查询。这种方式提高了查询性能,但增加了数据一致性和同步复杂性。
- 事件溯源与事件驱动架构:微服务通过发布领域事件来通知数据变更,其他服务订阅这些事件并更新自己的本地数据副本(物化视图)。查询时可以直接访问本地副本,避免实时跨服务调用。这种方法支持松耦合和高可扩展性,但需要处理事件顺序和最终一致性。
- 数据联邦与查询引擎:使用如Apache Drill、Presto等工具,它们能够虚拟化多个数据源(如不同微服务的数据库),提供统一的SQL查询接口。引擎在后台执行跨服务查询和连接,对用户透明。适合复杂分析场景,但可能对性能有影响,且需要管理数据源连接。
- API网关与BFF(后端为前端)模式:在API网关层或专门为前端定制的BFF服务中,整合多个微服务的调用,为客户端提供统一的查询接口。这可以优化网络请求,并减少客户端的复杂性。
- 分布式事务与Saga模式:对于需要强一致性的查询,可以使用Saga模式管理跨服务的事务,但通常更适用于写操作。在查询场景中,更推荐采用最终一致性方案,通过补偿机制处理数据不一致问题。
实践中,选择哪种方法取决于具体需求,如查询频率、数据一致性要求、延迟容忍度等。通常,混合使用多种策略是可行的,例如结合CQRS和事件驱动来处理高频查询,同时用API组合处理简单场景。关键是要在设计时明确服务边界,并确保数据所有权清晰,避免服务间过度耦合。监控和日志记录对于调试跨服务查询问题至关重要,可以使用分布式追踪工具(如Jaeger、Zipkin)来跟踪请求链路。
跨微服务数据查询是微服务架构中的常见挑战,但通过合理的设计模式和技术选型,可以构建出高效、可维护的解决方案。重点在于权衡一致性、可用性和性能,并根据业务需求灵活调整策略。