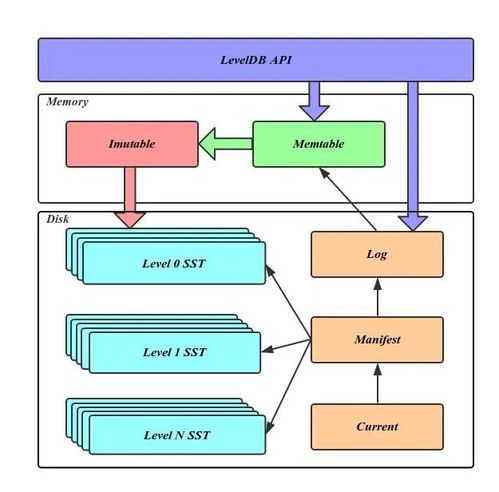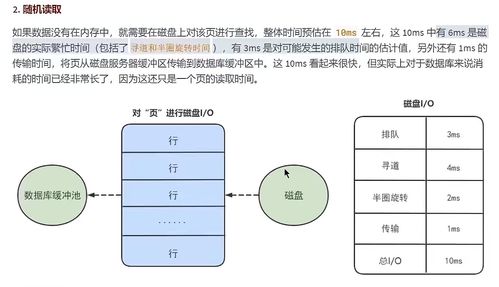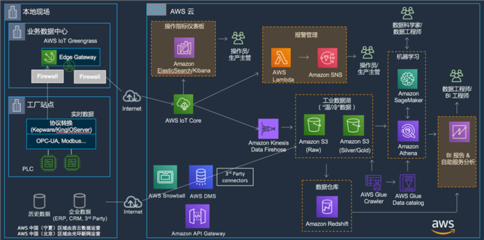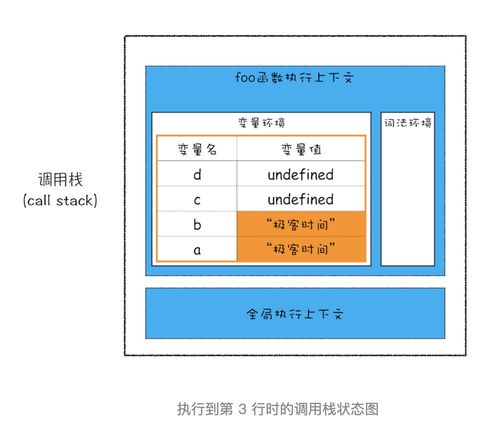
在计算机科学中,数据的存储方式直接影响程序的性能和内存管理效率。栈空间和堆空间是两种核心的内存分配区域,它们各自承担不同的职责,共同支撑着数据处理与存储服务的高效运行。
一、栈空间:快速且有序的存储方式
栈空间是一种线性数据结构,采用后进先出(LIFO)的原则进行数据存取。它主要用于存储局部变量、函数参数和返回地址等临时数据。栈空间的分配和释放由编译器自动管理,无需程序员手动干预。当函数被调用时,其局部变量会被压入栈中;函数执行完毕后,这些变量会自动弹出,释放内存。
栈空间的特点:
- 速度快:由于内存分配和释放的顺序固定,栈操作通常非常高效。
- 空间有限:栈的大小通常较小,过度使用可能导致栈溢出错误。
- 自动管理:无需手动释放内存,降低了内存泄漏的风险。
二、堆空间:灵活且动态的存储方式
堆空间是一种非结构化的内存区域,用于存储动态分配的数据,如对象、数组等。堆空间的分配和释放需要程序员手动管理(在C/C++等语言中),或由垃圾回收机制自动处理(如Java、Python)。堆内存的访问速度相对较慢,因为它涉及更复杂的内存管理操作。
堆空间的特点:
- 灵活性高:可以动态分配和释放内存,适合存储大小不确定的数据。
- 空间较大:堆内存通常比栈空间大得多,可以容纳更多数据。
- 管理复杂:手动管理堆内存可能导致内存泄漏或悬空指针等问题。
三、数据在栈与堆中的存储示例
以C语言为例,局部变量通常存储在栈中:`c
void exampleFunction() {
int localVar = 10; // 存储在栈中
}`
而动态分配的内存则存储在堆中:`c
int dynamicVar = (int)malloc(sizeof(int)); // 存储在堆中`
四、数据处理与存储服务的应用
在现代数据处理与存储服务中,栈和堆的概念被广泛应用。例如:
- 数据库管理系统:栈用于管理查询执行中的临时数据,堆用于存储大量的表数据和索引。
- 云计算服务:虚拟机的内存管理通常涉及栈和堆的优化,以提高资源利用率。
- 大数据处理框架:如Apache Spark,在执行任务时利用栈管理任务状态,堆则存储分布式数据集。
五、优化建议
- 合理使用栈和堆:对于小型、短生命周期的数据,优先使用栈;对于大型、长生命周期的数据,使用堆。
- 避免内存泄漏:在使用堆内存时,确保及时释放不再使用的资源。
- 监控内存使用:利用工具(如Valgrind、JVM监控)检测栈溢出和堆内存问题。
栈空间和堆空间是数据存储的基石,理解它们的区别与应用场景,有助于开发高效、稳定的数据处理与存储服务。通过合理利用这两种内存区域,可以显著提升系统性能和可靠性。