时序数据(Time-Series Data)作为一种按时间顺序记录的数据类型,广泛存在于物联网监控、金融交易、系统日志等场景中。为高效管理海量时序数据,阿里云Tablestore提供了专门的时序数据存储解决方案。本文将从数据处理与存储服务的角度,深入剖析其核心架构设计。
1. 时序数据的特点与挑战
时序数据通常具有以下特征:数据按时间戳顺序写入、数据量巨大且持续增长、数据时效性强(近期数据访问频繁,历史数据访问较少)、数据模式相对固定(通常包含时间戳、数据源标识和度量值)。这些特点对存储系统提出了高吞吐写入、低成本存储、高效时间范围查询等核心要求。
2. Tablestore时序存储架构概览
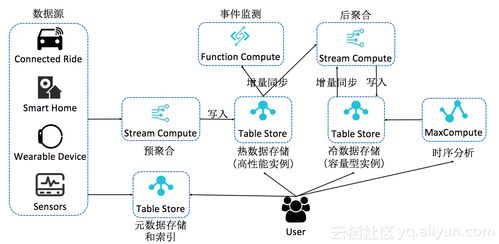
Tablestore时序存储采用分层架构设计,整体可分为数据处理层和存储服务层,两者协同工作以应对时序场景的特殊需求。
2.1 数据处理层
数据处理层负责接收、缓冲、预处理和路由时序数据,主要包含以下组件:
- 接入网关:提供多种协议接入能力,支持HTTP、SDK等多种方式写入数据,并对请求进行初步验证和限流。
- 数据预处理器:对写入的时序数据进行格式校验、时间戳规范化等预处理操作,确保数据符合存储规范。
- 分区路由器:基于数据源标识和时间范围,智能地将数据路由到合适的存储节点,实现数据的均匀分布和高效查询。
- 写入缓冲队列:采用内存缓冲和批量写入机制,将小批量写入聚合成大批量操作,显著提升写入吞吐并降低存储压力。
2.2 存储服务层
存储服务层是时序数据的持久化存储核心,采用创新的存储结构以满足时序数据的访问模式:
- 时序表设计:每个时序表按“数据源+时间区间”进行自动分区,每个分区独立存储和扩展。这种设计既保证了同一数据源在时间维度上的数据局部性,又避免了单一分区过大导致的性能瓶颈。
- 多级存储引擎:
- 热存储层:采用高性能SSD存储近期频繁访问的数据,提供低延迟读写能力。
- 温存储层:存储访问频率较低的历史数据,采用高容量HDD实现成本与性能的平衡。
- 冷存储层:存储极少访问的长期归档数据,采用对象存储等更低成本的介质,并通过生命周期策略自动迁移数据。
- 索引与元数据管理:
- 时序索引:为每个数据源建立时间线索引,支持按时间范围和标签属性快速定位数据块。
- 元数据存储:独立存储数据源的元信息(如标签、统计信息等),加速查询过滤和数据管理操作。
3. 数据处理与存储的协同优化
Tablestore时序存储通过数据处理层与存储服务层的紧密协作,实现了多项性能优化:
- 写入优化:数据处理层的缓冲队列与存储层的批量提交机制结合,将随机写入转换为顺序写入,充分利用存储介质的特性。
- 查询优化:分区路由器与存储索引的配合,使得时间范围查询能够精准定位到少数分区,避免全表扫描。
- 存储成本优化:基于访问模式的数据自动分层,在保证性能的同时显著降低存储成本。系统自动监控数据访问频率,将冷数据迁移至低成本存储层。
- 弹性扩展:数据处理层无状态设计支持水平扩展,存储层分区机制支持存储容量的无缝扩展,整个系统可随数据量增长线性扩展。
4. 典型应用场景与最佳实践
该架构已成功应用于多个高负载时序场景:
- 物联网设备监控:百万级设备持续上报状态数据,系统稳定处理日均TB级写入,并提供实时查询能力。
- 应用性能监控:收集分布式系统的性能指标,支持多维度的聚合分析与异常检测。
- 金融行情数据:存储高频交易数据,提供毫秒级的历史行情查询服务。
最佳实践建议包括:合理设计数据源标识以实现数据均匀分布;根据查询模式设置合适的数据保留策略;利用预聚合减少重复计算等。
5.
Tablestore时序数据存储通过分层架构设计,在数据处理层实现了高吞吐接入和智能路由,在存储服务层实现了高效存储和低成本归档。两者协同工作,为时序数据场景提供了高性能、高可靠、低成本的完整解决方案。随着5G和物联网技术的发展,时序数据存储将继续演进,在实时分析、智能预测等方向提供更强大的能力支持。